Hoy vamos a explicar las diferencias que existen entre un CRM (Customer Relationship Management) tradicional y un CRM inteligente aplicando tecnologí [...]
Leer más »Los métodos de clustering, o agrupamiento, son una pieza fundamental en el proceso de análisis de los datos, pues permiten una segmentación automática de la información de la que se puede extraer conclusiones muy valiosas.
Debido a su importancia han sido ampliamente estudiados, de ahí que existan cientos de algoritmos y distintas formas de clasificarlos(1). Una forma sería dividirlos en dos grupos, aquellos que únicamente abordan la tarea del agrupamiento, y aquellos que además incluyen ciertas ventajas en la visualización y el entendimiento de la información.
En este artículo entenderás qué es el clustering, cómo funciona y de qué manera este método puede ser de gran ayuda para el análisis de los datos.
El clustering es un proceso en el cual se trata de agrupar distintos objetos con características similares en grupos llamados clusters. Lo habitual es no conocer la salida de los objetos que se quieren agrupar, por lo que se llevará a cabo a través de entrenamiento no supervisado.
Esta tarea puede parecer sencilla cuando se tiene un número de características muy pequeño, pero lo cierto es que a medida que se tiene un número de variables mayor, las relaciones posibles entre cada objeto se vuelven más complejas y difíciles de analizar.
No es un problema con solución directa, por lo que requiere de un proceso iterativo que variará según el algoritmo de agrupamiento.
Para agrupar objetos primero se tienen que encontrar ejemplos similares. Medir esta similitud de las muestras se hace con una función de similitud, que habitualmente es una función de distancia entre los vectores de características que forman la muestra.
Una vez se establece la medición de la similitud, el proceso de agrupar depende del tipo de algoritmo. Los más comunes se clasifican en agrupamiento jerárquico, basados en centroide, basados en distribuciones y basados en densidad.
Uno de los algoritmos más conocidos es el de k-means, basado en centroide. El funcionamiento es sencillo, cada cluster se definirá con un objeto prototipo que puede o no ser miembro del conjunto de datos, y será el centroide del grupo. Una vez se define el número de clusters, el problema es el de encontrar estos centros tal que el cuadrado de las distancias del grupo al objeto prototipo estén minimizadas. Se lleva a cabo un proceso iterativo donde se asignan muestras a los grupos y se van actualizando los centros hasta que las asignaciones dejen de cambiar.
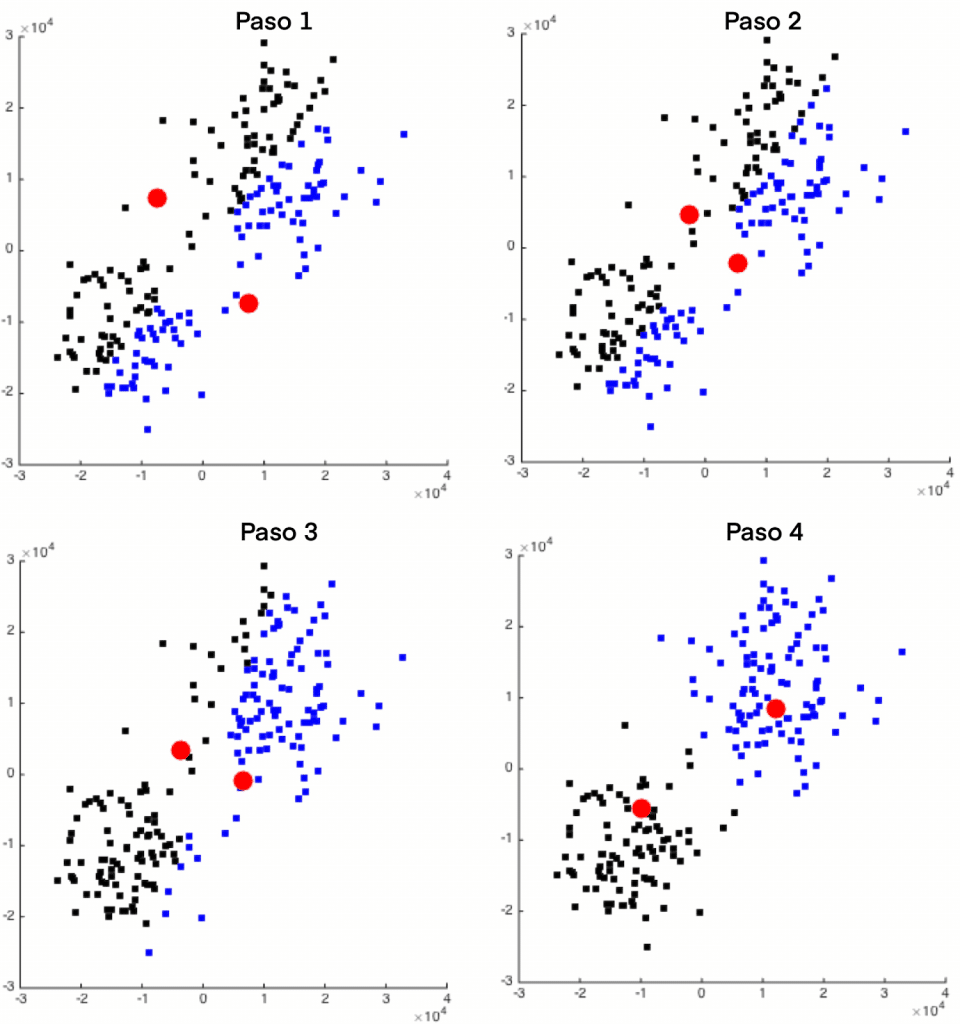
Se pueden destacar dos tipos de utilidades que se le pueden dar al agrupamiento de las muestras de los datos:
Centrándonos en esta primera utilidad, el análisis de clusters puede realizarse a través de la segmentación realizada. Pero además, existen métodos de clustering que aportan una serie de ventajas adicionales para extraer aún más información de los datos.
Estos métodos pueden permitir visualizar en mapas de baja dimensión (típicamente 2D) datos de alta dimensión a través de realizar un mapeo suave, no lineal, de ambos espacios. A esta propiedad se le conoce como reducción de la dimensionalidad y permite preservar la información sobre la distribución de los datos de entrada y observar las relaciones de las variables en distintos mapas.
De esta forma, se pueden comparar distintas muestras y moverlas en estos mapas para observar el cambio suave en sus características.
Esta característica que poseen algunos métodos de agrupación es muy importante en la mayoría de aplicaciones de clusters y lleva a un análisis de los datos más profundo y fácil de entender.
Esto se ve mejor con un ejemplo. En la siguiente imagen se pueden observar cómo son estos mapas 2D una vez ya organizada la información con el algoritmo de clustering. Donde cada casilla caracteriza al grupo de individuos que caen en ella y se representan sus variables a través de los distintos mapas.
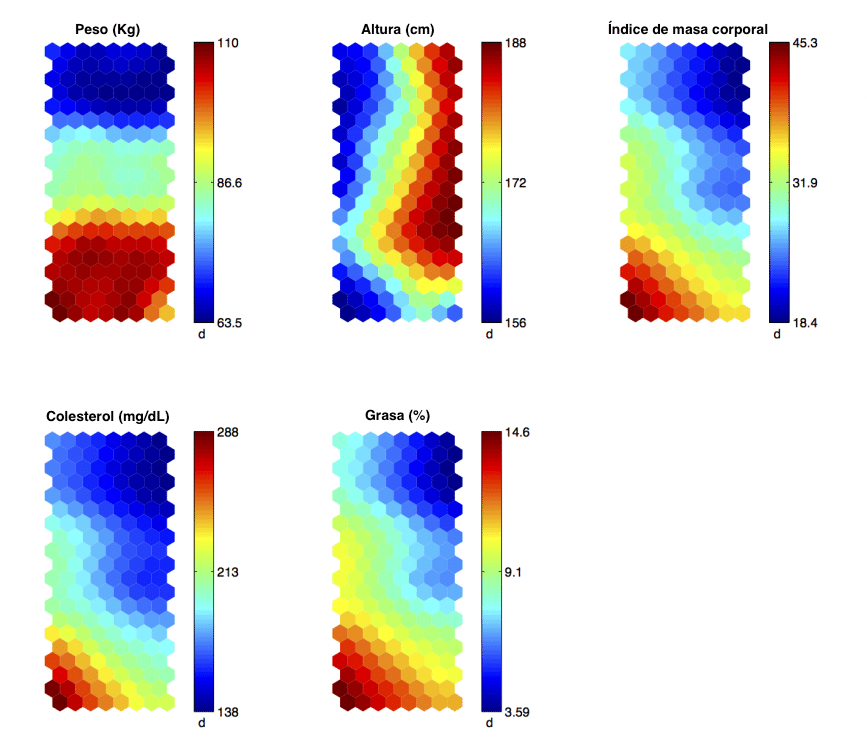
En estos mapas se aprecian variables médicas de las personas como el peso, altura, índice de masa corporal, colesterol y porcentaje de grasa.
Así pues, una vez aplicado el algoritmo se pueden extraer conclusiones tales como que los individuos con un peso alto (más de 100 Kg), baja estatura (menos de 162 cm) tienen un índice de masa corporal, un nivel de colesterol y un porcentaje de grasa elevado, por lo que se podría considerar como un grupo de riesgo alto.
Este es un ejemplo muy reducido, en un caso real se podría conocer el historial médico de los pacientes y un número mayor de variables para obtener mejores conclusiones más valiosas.
Si por ejemplo se quisiera conocer qué variables influyen en que se produzca un infarto se podría añadir variables como el número de infartos sufridos o el tipo de infarto. Aplicar el algoritmo de clustering ayudaría a encontrar diferentes grupos de individuos y las características que los diferencian.
No solo eso, sabiendo cuales son las variables sobre las que se puede actuar, conocidas como palancas, gracias a los mapas podríamos saber qué valor deberían tener para mover el comportamiento hacia donde nosotros deseemos. Sabiendo además como se cambiarían el resto de variables.
Otros análisis que permiten estos mapas sería el de conocer las variables que más difieren o se parecen en grupos próximos, viendo de forma gradual su cambio.
La segmentación de muestras según sus propiedades pueden ser usadas en cualquier aplicación en la que se quieran relacionar muestras no clasificadas o se quieran analizar en profundidad datos no estructurados. Entre algunas de las aplicaciones se encuentran:
_
Hoy vamos a explicar las diferencias que existen entre un CRM (Customer Relationship Management) tradicional y un CRM inteligente aplicando tecnologí [...]
Leer más »Las oportunidades de negocio están en todas partes y muchas veces no sabemos cuales son los sectores con mayor potencial para el emprendimiento. [...]
Leer más »El término inteligencia artificial (IA) es pura actualidad, pero fue inventado en 1956 por John McCarthy, Marvin Minsky y Claude Shannon en la famosa [...]
Leer más »El auge de la Inteligencia Artificial (IA) en los negocios está muy de actualidad. Su uso se está extendiendo y está cambiando, incluso, los modelo [...]
Leer más »
